Why Learn from Predictions?
Every time a self-driving fleet adopts a new sensor, or expands into a new city, the same expensive ritual repeats: collect data, annotate it in 3D, retrain. We wanted to know whether this cycle is actually necessary. Nearby vehicles, robotaxis, and roadside systems frequently already carry detectors tuned to the local area, and what they know is easy to share: a predicted 3D box is compact and standardized in a way that raw point clouds or model weights are not.
Learning from those predictions instead of raw sensor data has three properties we care about. It is label-efficient, because supervision comes from another agent's detections rather than from annotating the ego stream from scratch. It is sensor-agnostic, because the reference and ego vehicles need not share a LiDAR pattern or even a detector architecture. And it is communication-efficient, since only a handful of 3D boxes cross the link, while training and deployment stay entirely on the ego side.
Two unavoidable gaps
It would be convenient if we could simply treat a reference vehicle's predictions as ground truth. In practice, two gaps stand between us and that convenience.
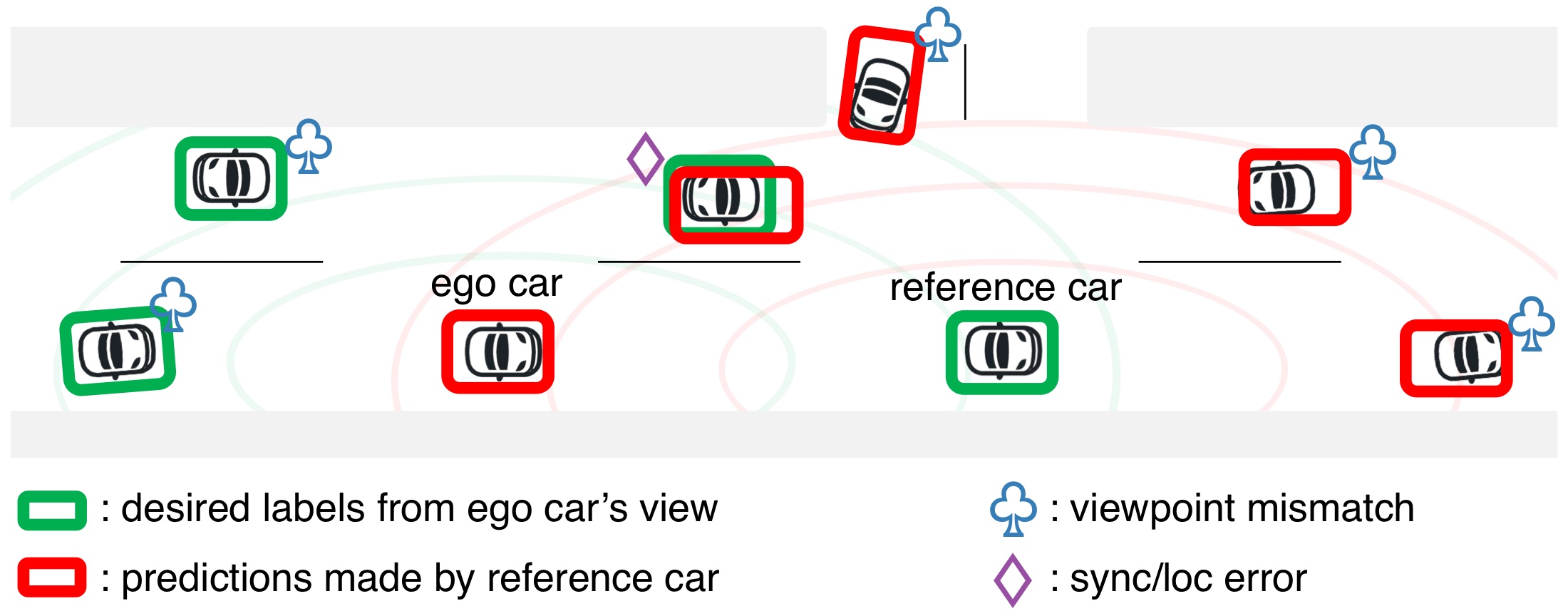
The first is geometric: GPS error and synchronization delay shift reference boxes away from where the ego vehicle actually observes the same object. The second is one of visibility: occlusion and limited sensing range mean plenty of objects are seen by only one of the two vehicles, never both. Treating reference predictions as labels without accounting for either one means inheriting both problems at once.
Refine Boxes, Then Discover More
R&B-POP is built around a simple idea: treat the two gaps separately rather than solving them at once. A label-efficient ranker handles localization noise directly, while a distance-based curriculum handles the harder problem of objects the reference vehicle never saw at all.
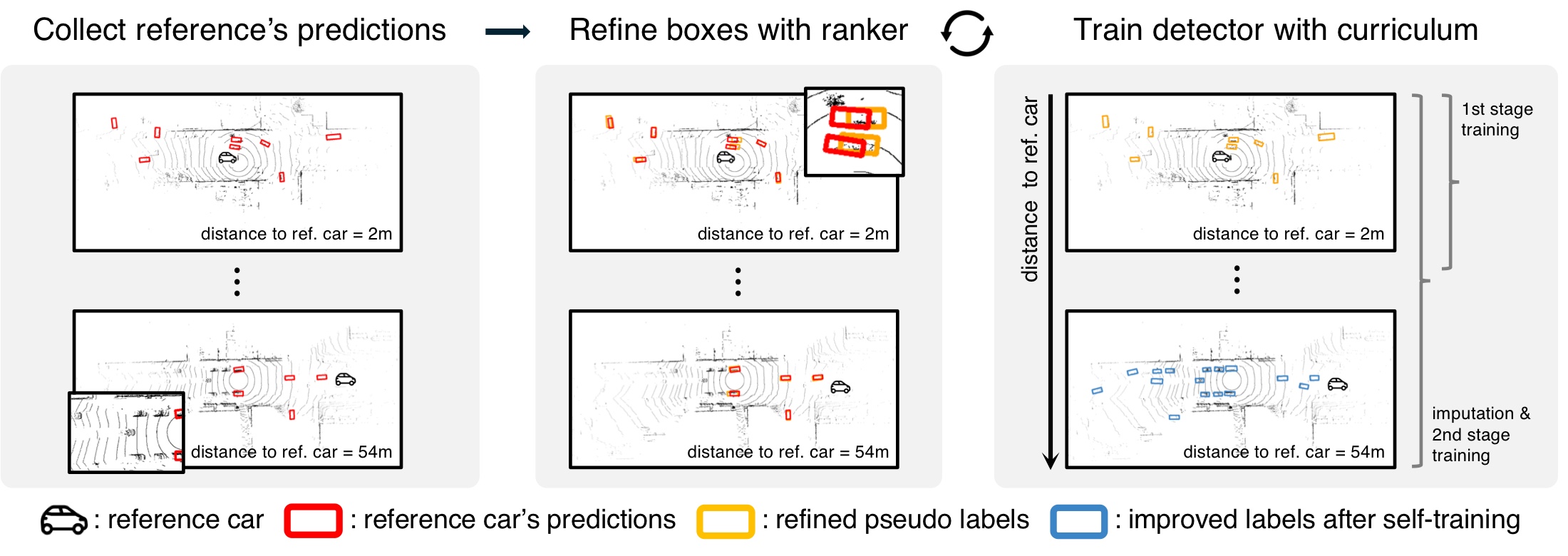
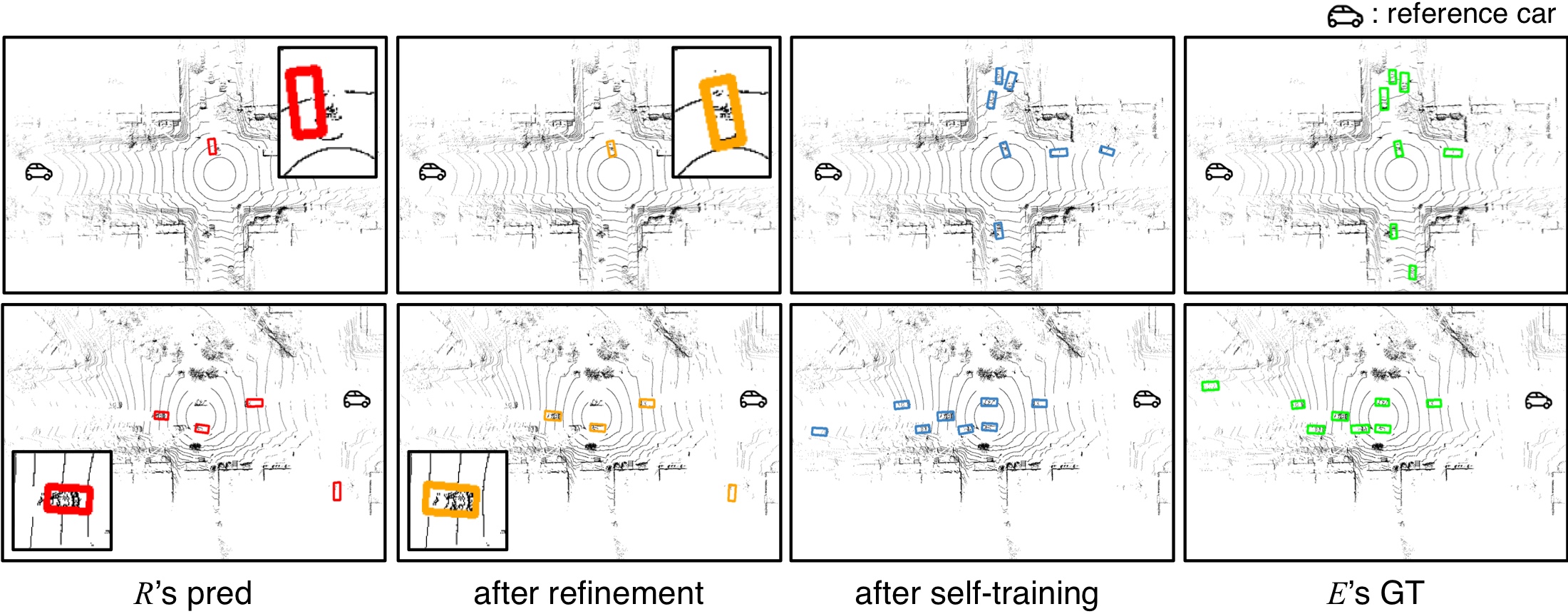
The pipeline unfolds in three stages, and only the first happens online. While the ego vehicle is actually driving, it collects predictions by transforming the reference agent's boxes into the ego coordinate frame—a lightweight exchange of boxes rather than raw sensor data. Everything from here on happens offline, after the drive. The pipeline first refines localization: candidates are sampled around each noisy box, and a learned IoU ranker picks whichever one best matches the true object extent, using no more than 1% labeled frames to learn how. Then it discovers what the reference vehicle missed—starting from the closest, most reliable reference labels, the detector self-trains with a distance-based curriculum until it recovers objects unique to its own view.
A small ranker does the precise correction
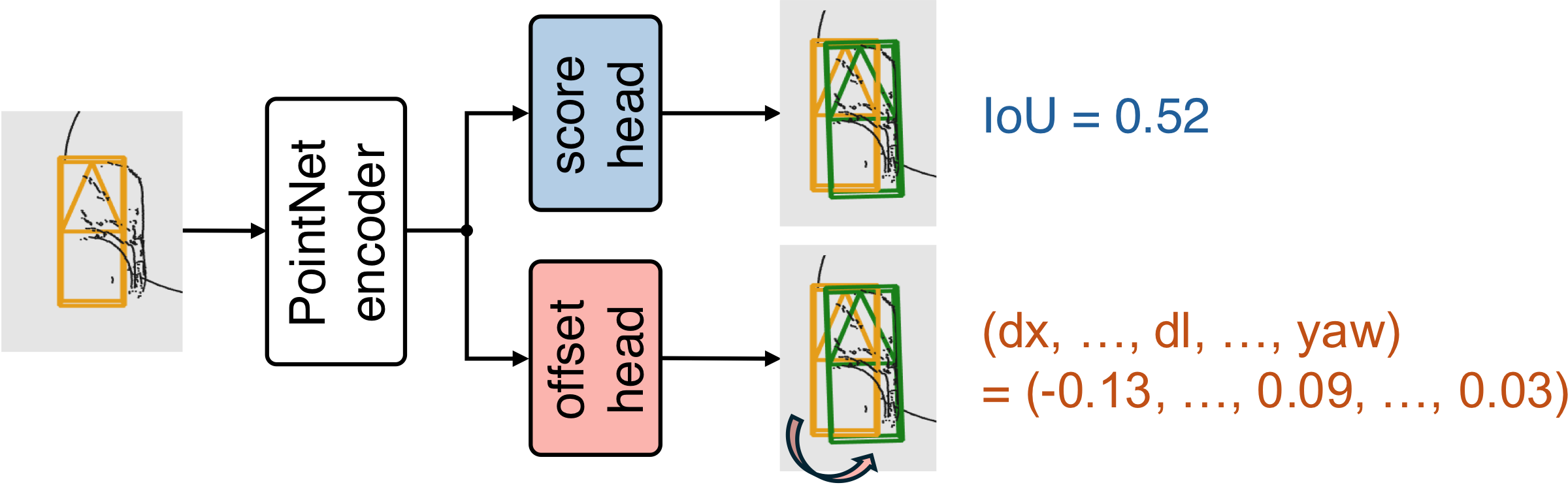
Why would a ranker need so much less data than the detector it is helping to correct? Because ranking is a much easier problem than detecting. Given a noisy reference box and a handful of candidates sampled around it, deciding which candidate best matches the true object extent leans much more on geometric shape and fit than on deep understanding of raw sensor data. That gap in difficulty is what lets the ranker learn from a small amount of supervision, and sometimes from none at all.
Concretely, the ranker is a small PointNet encoder reading the current pseudo-label together with the points around it, feeding two lightweight heads: a score head that predicts the candidate's IoU with the true object, and an offset head that regresses a residual correction—a small translation and yaw adjustment—to sharpen the candidate further.

Nearly Closing the Supervision Gap
Taken at face value, reference predictions are a poor substitute for labels: training directly on them reaches only 22.0 AP. Correcting for localization noise and recovering missed objects closes most of that distance—R&B-POP reaches 56.5 AP, within a few points of the 58.4 AP ceiling set by a detector trained on full ego ground truth.
Evaluated on real-world collaborative driving
We evaluate on V2V4Real, a real-world dataset of paired driving scenes: two nearby cars, each with an independent 32-beam LiDAR stream, at distances spanning 0–100 m, both running a PointPillars detector. Of the two, we designate one as the reference car and assume it already carries a well-trained detector. The other, the ego car, sees the same scene from its own vantage point and uses only the reference car's predictions—never its own annotations—to pseudo-label its sensor stream.
| Supervision | Box refinement | Self-training | AP@0.5 | AP@0.7 |
|---|---|---|---|---|
| Reference predictions | — | — | 22.0 | 4.2 |
| Reference predictions | Ranker | Naive | 45.0 | 28.0 |
| Reference predictions | Ranker | Distance curriculum | 56.5 | 32.6 |
| Ego ground-truth | — | — | 58.4 | 36.3 |
Citation
@inproceedings{yoo2025rnbpop,
title={Learning 3D Perception from Others' Predictions},
author={Yoo, Jinsu and Feng, Zhenyang and Pan, Tai-Yu and
Sun, Yihong and Phoo, Cheng Perng and Chen, Xiangyu and
Campbell, Mark and Weinberger, Kilian Q. and
Hariharan, Bharath and Chao, Wei-Lun},
booktitle={International Conference on Learning Representations (ICLR)},
year={2025}
}