
|
Jinsu Yoo - I'm a Ph.D. student at The Ohio State University advised by Wei-Lun (Harry) Chao. My research develops affordable and robust 3D spatial intelligence models focused on perception, enabling reliable intelligent systems under real-world constraints such as limited sensor data, diverse environments, and safety-critical requirements. I’m currently seeking a research internship—any opportunities or referrals would be greatly appreciated! Please feel free to reach out! (2025.09) / / / / |
|
|
|
|

|
Study of continual unlearning for text-to-image diffusion models with regularizers that prevent drift and maintain semantic fidelity.
|
|
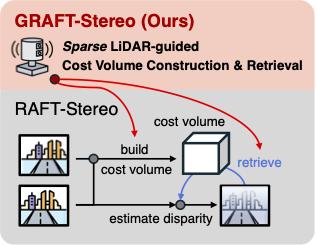
With minimal architectural changes and an analysis of RAFT-Stereo's internal mechanism, we show it can be effectively adapted for LiDAR-guided stereo.
|

|
Label-efficient fine-grained segmentation for biological specimen images.
|
|
Diffusion-based point cloud generation to synthesize collaborative driving data.
|
|
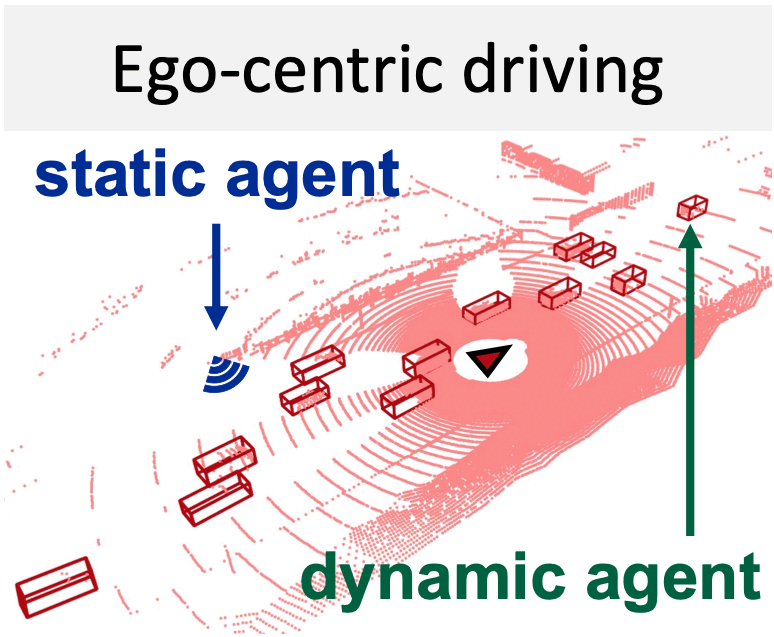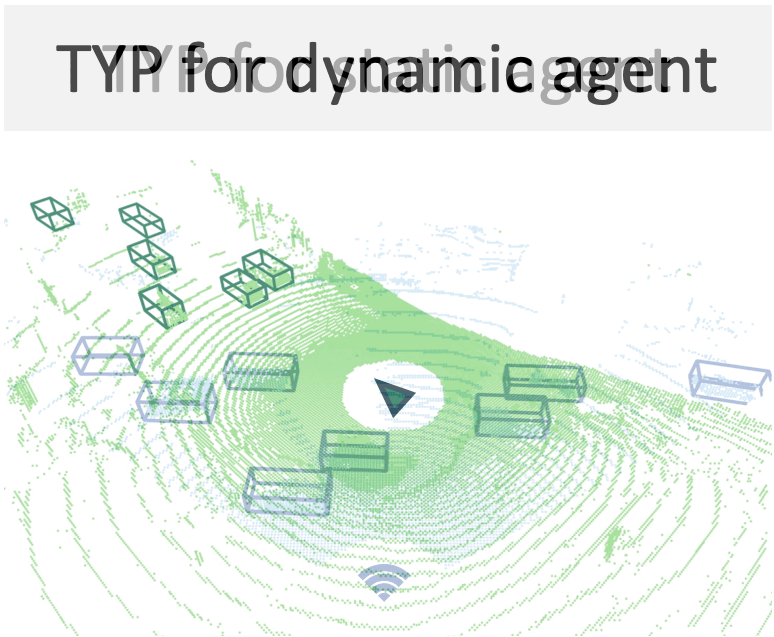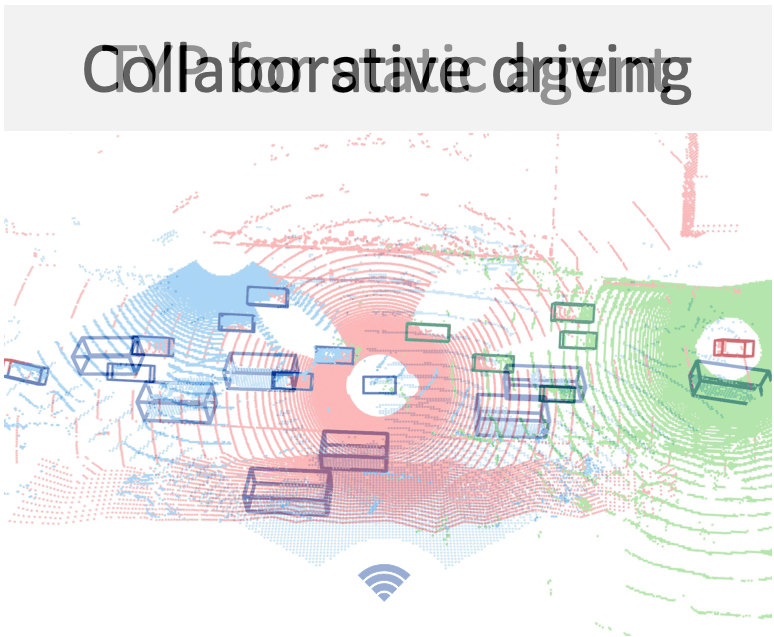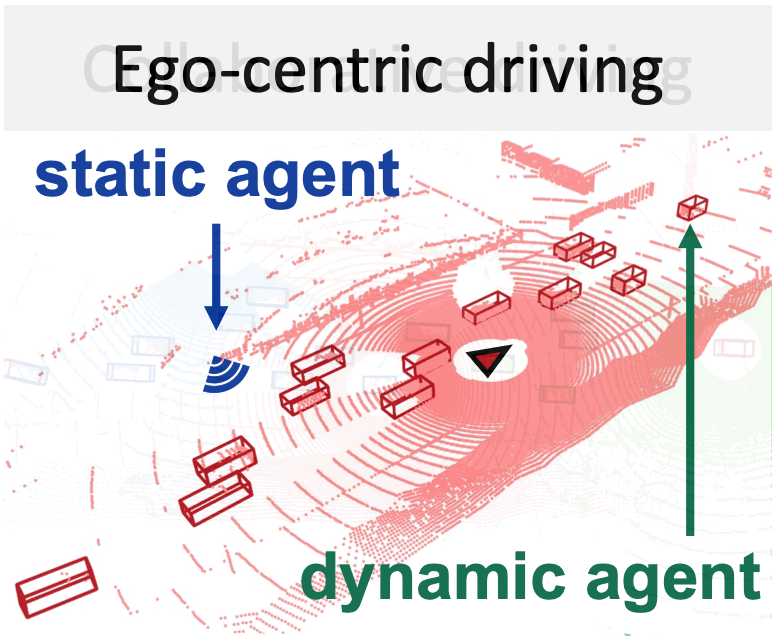
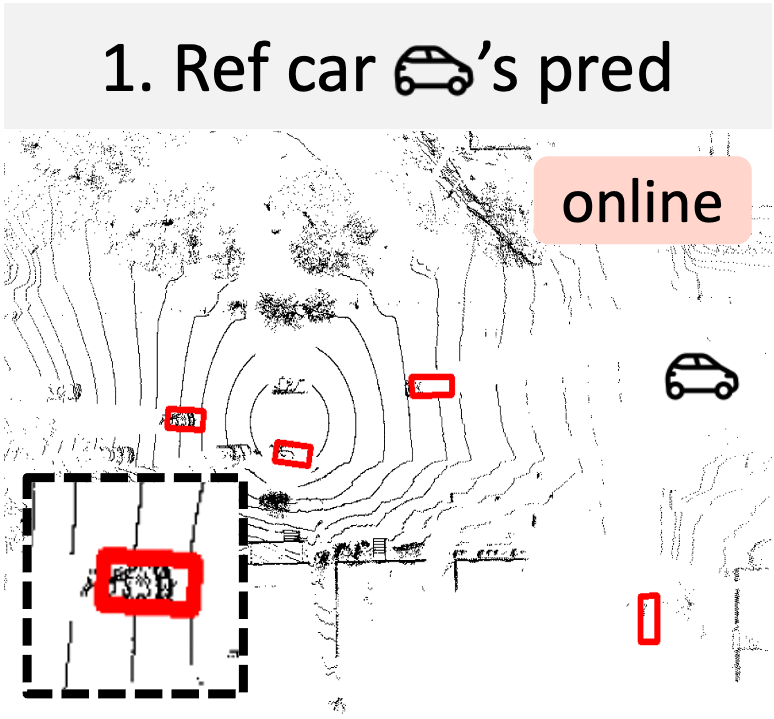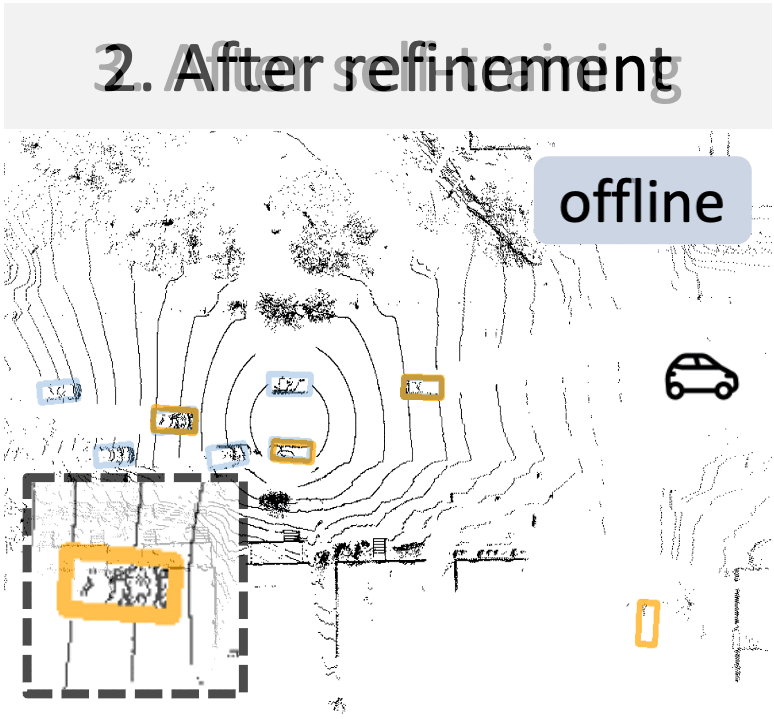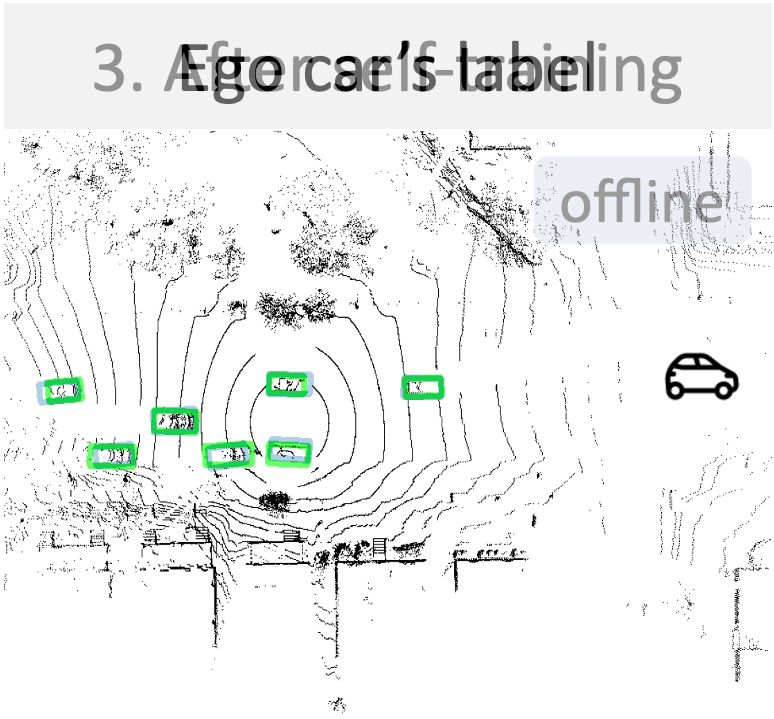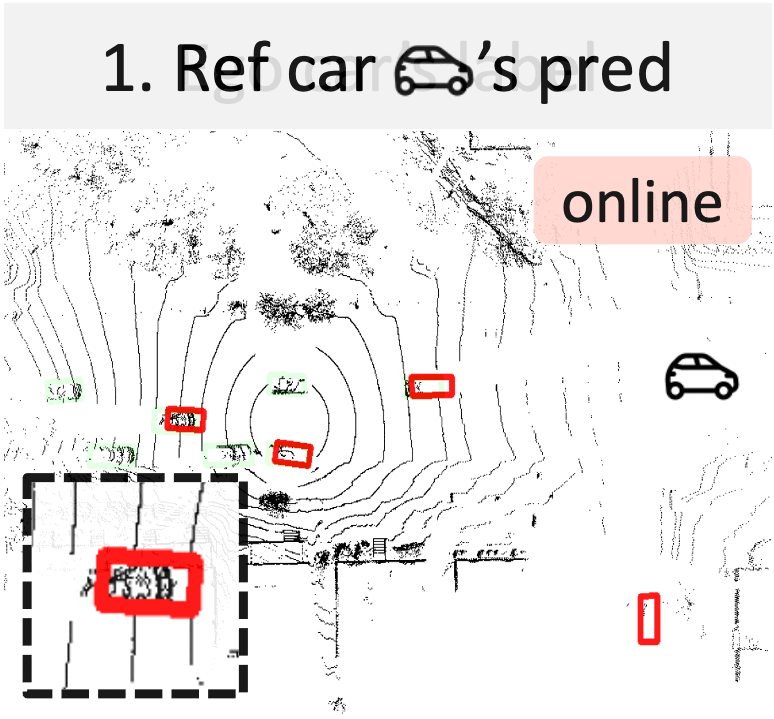
A new way to build ego 3D object detectors: learning from the predictions of nearby expert agents.
|
|
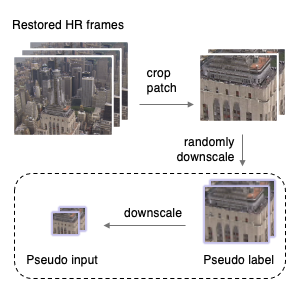
Restored video frames can be used as pseudo-labels during test time.
|
|
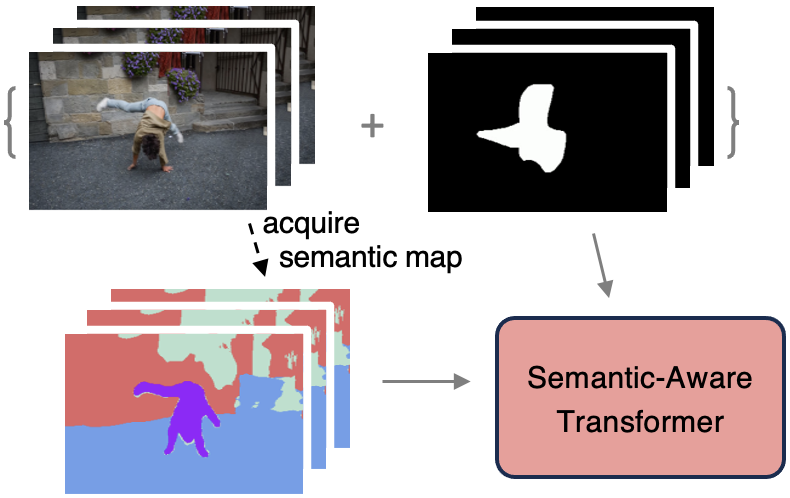
Combining semantic maps with video inpainting helps produce better results.
|
 
|
Combining CNN and ViT features improves image restoration.
|
|
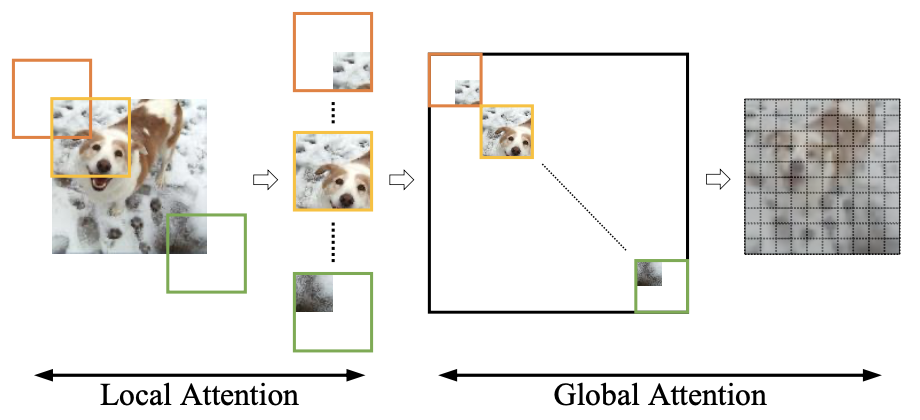
Flexible and versatile attention mechanism for dense prediction.
|
 
|
Meta-learning the SR networks allows the model to adapt efficiently to each test image.
|
|
|
|
Conference Reviewer: CVPR, ICCV, ECCV, NeurIPS, WACV, ACCV
🏆 Outstanding Reviewer in ECCV 2022, 2024 |
|
|
|
🏃 I enjoy running. In my free time, I tend to run on a treadmill and have occasionally participated in local marathons. Someday I hope to complete an entire six stars (Tokyo, Boston, London, Berlin, Chicago, and NYC)! Here are my (selected) records so far: Half 1:59:37 (Seoul, 2016), 10km 54:58 (Seoul, 2023), 10km 57:20 (Hot Chocolate Run - Columbus, 2023) |
|
Template inspired from Jon Barron and Chris Agia. This page has been visited
|