
|
Jinsu Yoo - I am a first-year computer science PhD student at The Ohio State University advised by Wei-Lun (Harry) Chao. I work on computer vision and machine learning. 🇰🇷 Before OSU, I received my master's and bachelor's degrees from Hanyang University, where I was fortunate to work with Tae Hyun Kim. Also, I had a wonderful time interning at LG AI Research. Email / CV / Google Scholar / LinkedIn / Github |
|
|
|
|
|
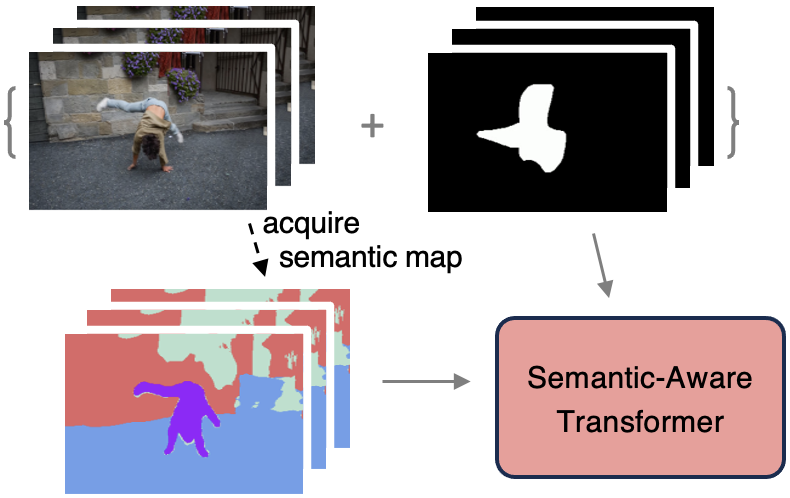
Semantic-Aware Dynamic Parameter for Video Inpainting Transformer
ICCV 2023 /
arXiv /
open access
tl;dr: Combining semantic maps with video inpainting helps produce restored frames with clearer semantic structures and textures.
|
 
|
Enriched CNN-Transformer Feature Aggregation Networks for Super-Resolution
tl;dr: Leveraging rich CNN and multi-scale ViT features together lets SR model restore the given image better.
|
|
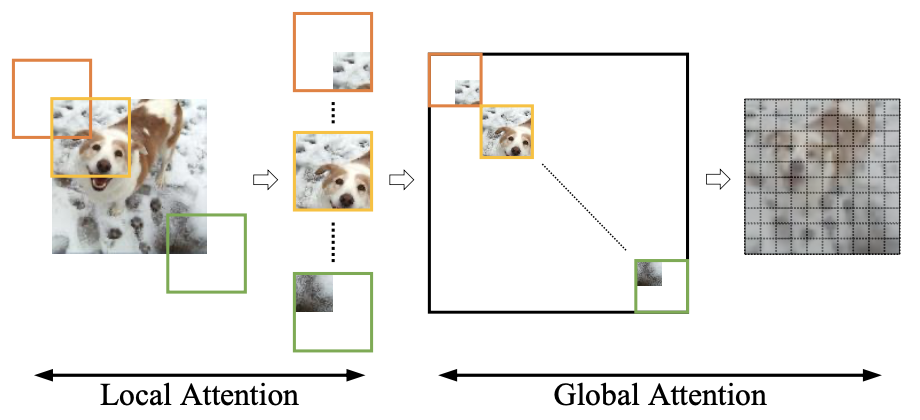
Fully Convolutional Transformer with Local-Global Attention
IROS 2022 /
paper
tl;dr: Flexible attention mechanism that can operate both upsampling and downsampling for dense prediction.
|
|
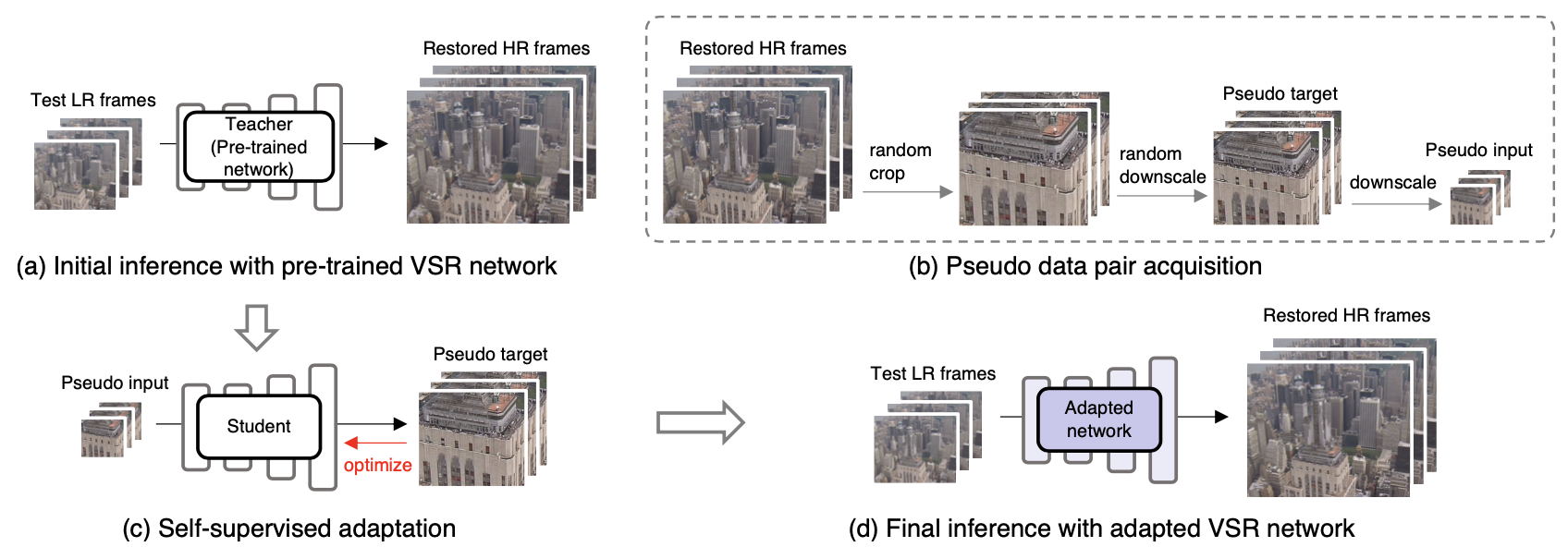
Self-Supervised Adaptation for Video Super-Resolution
tl;dr: Restored test video frames can be used as pseudo-labels for improving VSR network performance further.
|
 
|
Fast Adaptation to Super-Resolution Networks via Meta-Learning
tl;dr: Meta-learning can be used to train SR networks that can be efficiently adapted to each test image.
|
|
|
|
Conference Reviewer: CVPR, ICCV, ECCV, WACV, ACCV
🏆 Outstanding Reviewer in ECCV 2022 |
|
|
|
🏃 I enjoy running. In my free time, I tend to run on a treadmill and have occasionally participated in local marathons. Someday I hope to complete an entire six stars (Tokyo, Boston, London, Berlin, Chicago, and NYC)! Here are my (selected) records so far: Half 1:59:37 (Seoul, 2016), 10km 54:58 (Seoul, 2023), 10km 57:20 (Hot Chocolate Run - Columbus, 2023) |
|
Template modified from Jon Barron. This page has been visited
|